




We are thrilled to announce the release of Tower, a multilingual 7B parameter large language model (LLM) optimized for translation-related tasks. Tower is built on top of LLaMA2 [1] and currently supports 10 languages: English, German, French, Spanish, Chinese, Portuguese, Italian, Russian, Korean, and Dutch. It matches state-of-the-art models on translation as well as GPT3.5, and it surpasses larger open models, such as ALMA 13B [5] and LLaMA-2 70B. Tower also masters a number of other translation-related tasks, ranging from pre-translation tasks, such as grammatical error correction, to translation and evaluation tasks, such as machine translation (MT), automatic post-editing (APE), and translation ranking. If you’re working on multilingual NLP and related problems, go ahead and try Tower.
The training and release of the Tower model is a joint effort of Unbabel, the SARDINE Lab at Instituto Superior Técnico, and the MICS lab at CentraleSupélec at the University of Paris-Saclay. The goal of this release is to promote collaborative and reproducible research to facilitate knowledge sharing and to drive further advancements to multilingual LLMs and related research. As such, we are happy to:
-
Release the weights of our two Tower models: TowerBase and TowerInstruct.
-
Release the data that we used to fine-tune these models: TowerBlocks
-
Release the evaluation data and code: TowerEval, the first LLM evaluation repository for MT-related tasks.
From LLaMA2 to Tower: how we transformed an English-centric LLM into a multilingual one
Large language models took the world by storm last year. From GPT-3.5 to LLaMA and Mixtral, closed and open-source LLMs have demonstrated increasingly strong capabilities for solving natural language tasks. Machine translation is no exception: GPT-4 was among last year’s best translation systems for several language directions in the WMT2023’s General Translation track, the most established benchmark in the field.
Unfortunately, the story is not the same with current open-source models; these are predominantly built with English data and little to no multilingual data and are yet to make a significant dent in translation and related tasks, like automatic post-edition, automatic translation evaluation, among others. We needed to bridge this gap, so we set out to build a state-of-the-art multilingual model on top of LLaMA2.
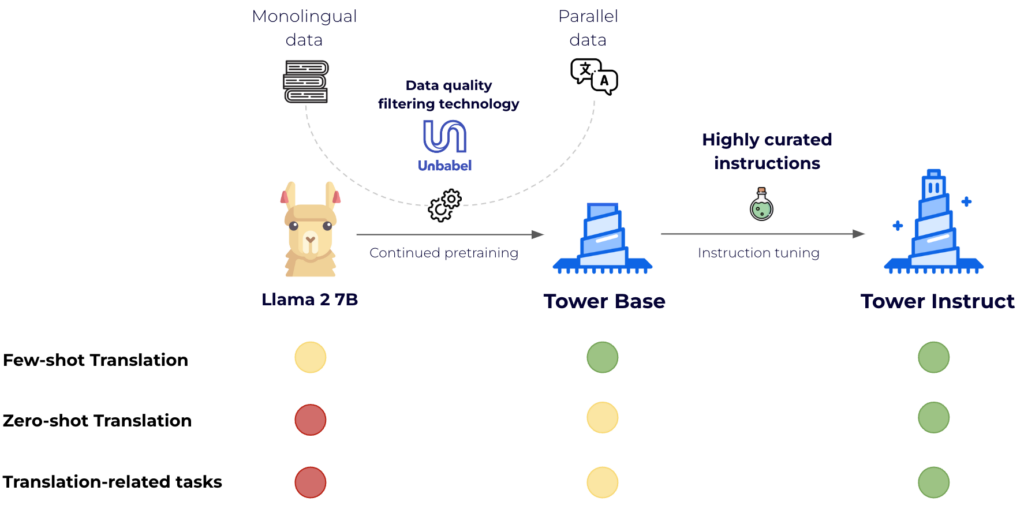
This required two steps: continued pre-training and instruction tuning. The former is essential to improve LLaMA2’s support to other languages, and the latter takes the model to the next level in terms of solving specific tasks in a 0-shot fashion.
For continued pretraining, we leveraged 20 billion tokens of text evenly split among languages. Two-thirds of the tokens come from monolingual data sources — a filtered version of the mc4 [3] dataset — and one-third are parallel sentences from various public sources such as OPUS [5]. Crucially, we leverage Unbabel technology, COMETKiwi [2], to filter for high-quality parallel data. The outcome is a significantly improved version of LLaMA2 for the target languages that maintains its capabilities in English: TowerBase. The languages supported by the current version are English, German, French, Chinese, Spanish, Portuguese, Italian, Dutch, Korean, and Russian.
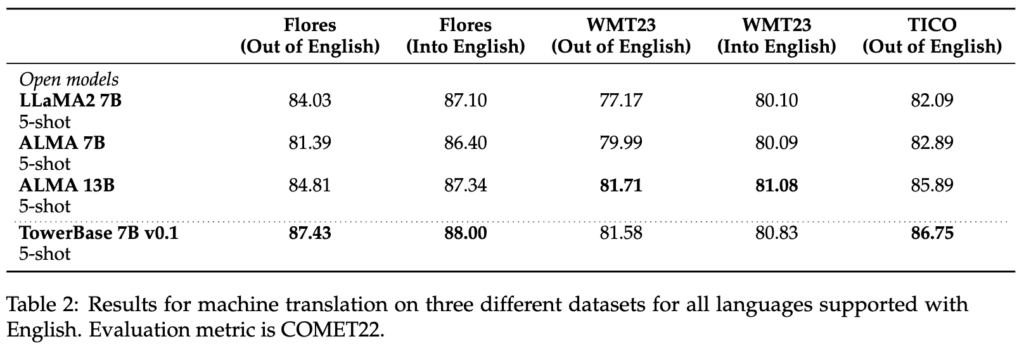
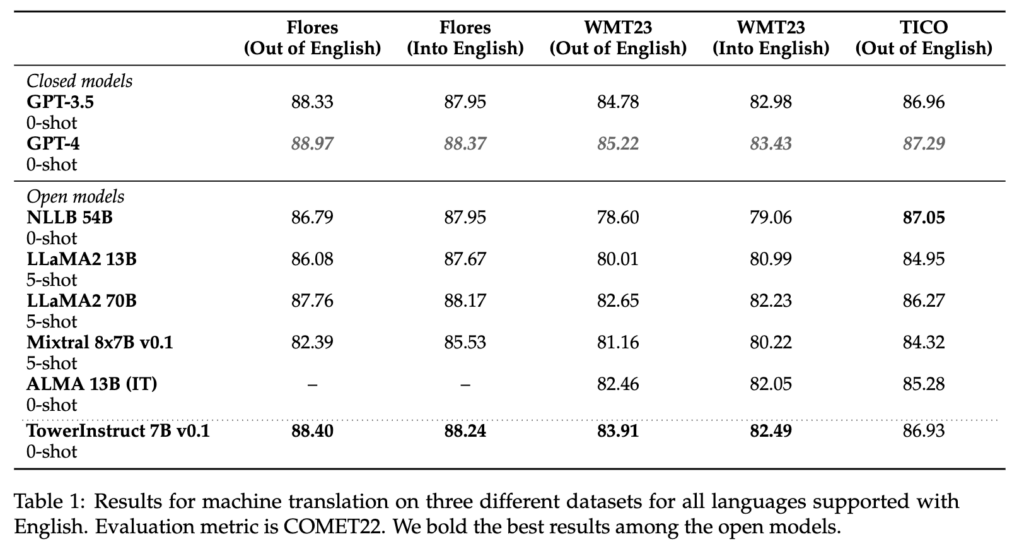
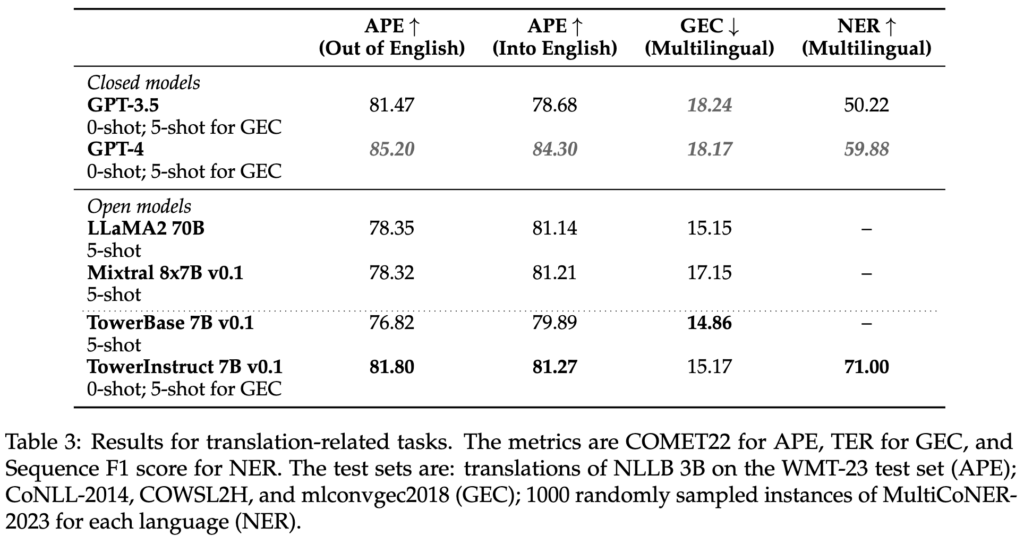
For supervised fine-tuning, we carefully constructed a dataset with diverse, high-quality task-specific records, as well as conversational data and code instructions. We manually built hundreds of different prompts across all tasks, including zero and few-shot templates. Our dataset, TowerBlocks, includes data for multiple translation-related tasks, such as automatic post edition, machine translation and its different variants (e.g., context-aware translation, terminology-aware translation, multi-reference translation), named-entity recognition, error span prediction, paraphrase generation, and others. The data records were carefully filtered using different heuristics and quality filters, such as COMETKiwi, to ensure the use of high-quality data at fine-tuning time. More than any other factor, this filtering, combined with careful choice of hyperparameters, played a crucial role in obtaining significant improvements over the continued pre-trained model. The resulting model, TowerInstruct, handles several tasks seamlessly in a 0-shot fashion — improving efficiency at inference time — and can solve other held-out tasks with appropriate prompt engineering. In particular, for machine translation, TowerInstruct is competitive and can outperform GPT3.5 and Mixtral 8x7B [6], whereas for automatic post-edition, named-entity recognition and source error correction, it outperforms GPT3.5 and Mixtral 8x7B across the board, and can go as far as outperforming GPT4.
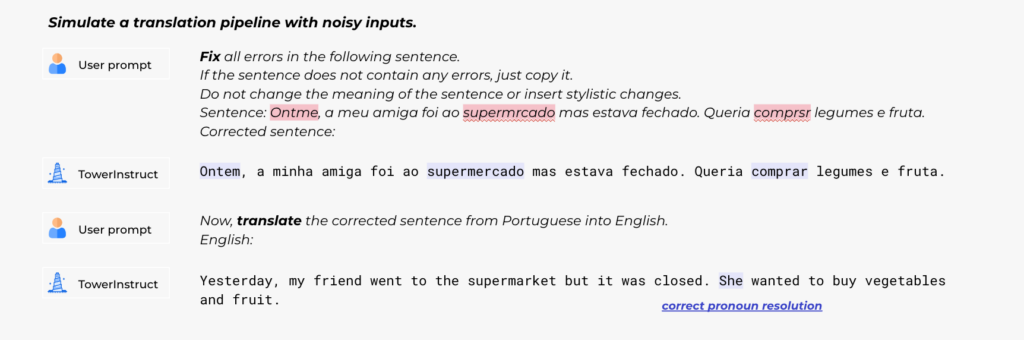


Using the Tower models
We are releasing both pre-trained and instruction-tuned model weights, as well as the instruction tuning and evaluation data. We will also release TowerEval, an evaluation repository focused on MT and related tasks that will allow users to reproduce our benchmarks and evaluate their own LLMs. We invite you to visit our Huggingface page and GitHub repository and start using them!
These Tower models are only the beginning: internally, we are working on leveraging Unbabel technology and data to improve our translation platform. Moving forward, we plan to make even more exciting releases, so stay tuned!
Acknowledgments
Part of this work was supported by the EU’s Horizon Europe Research and Innovation Actions (UTTER, contract 101070631), by the project DECOLLAGE (ERC-2022-CoG 101088763), and by the Portuguese Recovery and Resilience Plan through project C645008882- 00000055 (Center for Responsible AI). We thank GENCI-IDRIS for the technical support and HPC resources used to partially support this work.
References
[1] Llama 2: Open Foundation and Fine-Tuned Chat Models. Technical report
[2] Scaling up CometKiwi: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task. WMT23
[3] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
[4] Parallel Data, Tools and Interfaces in OPUS. LREC2012
[5] A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
[6] Mixtral of Experts


